Learning to Play: The Multi-Agent Reinforcement Learning
in MalmÖ (MARLÖ) Competition

This AIIDE workshop is centered on the MARLÖ competition on Multi-Agent Reinforcement Learning in MalmÖ. The aim of the competition is to foster research in agents that can learn to play a range of multi-agent games. This workshop is a key opportunity to raise awareness of the competition and associated research challenges within the AIIDE community, to brainstorm and discuss research directions in multi-task, multi-agent learning in modern video games, and to create a fertile ground for novel collaborations.
Program
This is a 1-day workshop which uniquely features the MARLO competition as is being run.
Key program elements are 2 invited talks, as well as short contributed talks and spotlight talks where competition participants give insights into the approaches their agents use. A short tutorial will allow interested attendees to get a hands on start to experimenting with MARLÖ competition agents. The conclusion of the day is a highlight, with announcement of the tournament winners and discussion with the winning teams.
The papers accepted would contribute to the AIIDE'18 Workshop Proceedings, including contributions from competition participants.
The program is as follows:
| When | What | By |
|---|---|---|
| 9:00 - 10:30 | MARLO Tutorial: Introductions and Hands-on | Diego Perez-Liebana |
| 10:30 - 11:00 | Coffee Break | |
| 11:00 - 11:50 | Keynote 1 - Game AI: The Appearance of Intelligence [Video] | Jesse Cluff (Coalition Games) |
| 11:50 - 12:10 | Like a DNA String: Sequence Mining for Player Profiling in Tom Clancy's The Division [Video] | Hendrik Baier |
| 12:10 - 12:30 | Modular Architecture for StarCraft II with Deep Reinforcement Learning [Video] | Dennis Lee |
| 12:30 - 14:00 | Lunch Break | |
| 14:00 - 14:50 | Keynote 2 - DeepStack: Expert-Level AI in Heads-Up No-Limit Poker | Martin Schmid (Google DeepMind) |
| 14:50 - 15:10 | Pommerman: A Multi-Agent Playground [Paper] [Video] | Cinjon Resnick et al. |
| 15:10 - 15:30 | Extending World Models for Multi-Agent Reinforcement Learning in MALMO [Paper] [Video] | Valliappa Chockalingam et al. |
| 15:30 - 16:00 | Coffee Break | |
| 16:00 - 16:45 | Discussion Panel | TBA |
| 16:45 - 17:00 | Closing |
Keynotes
Game AI: The Appearance of Intelligence
Jesse Cluff (The Coalition)

Abstract: Game AI has two defining characteristics. First, is that it is required to run in real time on machines with limited resources. The other characteristic of traditional Game AI is that it’s goal isn’t to win, but to maximize player enjoyment. One of the primary ways it does this is to provide a crafted challenge, matched to the player’s ability, that they understand, can anticipate, and plan for. These restrictions greatly impact which AI techniques are suitable and we’ll discuss why certain popular techniques are used. There are also many challenges in game AI that are active research areas. We’ll discuss these current challenges and what we are looking for in solutions. Finally, we’ll discuss multiplayer Bot AI and how it differs from single-player AI and how new technologies like machine learning could be applied to their development.
Bio: Jesse Cluff is the Principle Engineering AI Lead at The Coalition. He has been making games for 20 years, first starting as a Playstation graphics programmer at Radical Entertainment, but later pursuing AI after being inspired by Minsky’s “Society of Mind”. He has worked on titles that include Jackie Chan Stuntmaster, Dark Summit, Hulk, The Simpsons: Hit And Run, Bully, Space Marine, Company of Heroes 2, and Gears of War 4.
DeepStack - Expert-Level AI in Heads-Up No-Limit Poker
Martin Schmid (Google DeepMind)

Abstract: AI research has a long history of using games as a measure of progress towards intelligent machines, but attention has been focused primarily on perfect information games, like checkers, chess or go. But in real world, one has to deal with imperfect information. Poker is the quintessential game of imperfect information, where you and your opponent hold information that each other doesn't have (your cards). DeepStack bridges the gap between AI techniques for games of perfect information—like checkers, chess and Go—with ones for imperfect information games–like poker–to reason while it plays using “intuition” honed through deep learning to reassess its strategy with each decision. DeepStack is the first theoretically sound application of heuristic search methods—which have been famously successful in games like checkers, chess, and Go—to imperfect information games. With a study published in Science in March 2017, DeepStack became the first AI capable of beating professional poker players at heads-up no-limit Texas hold'em poker.
Bio: Previously worked as a Research Scientist at IBM Watson. His research deals with game theory, machine learning and artificial intelligence. Co-author of DeepStack, the first AI to beat professional poker players at heads-up no-limit Texas hold'em poker. https://kam.mff.cuni.cz/agtg/martin/
Call for papers
The AIIDE 2018 workshop on 'Learning to Play: The Multi-Agent Reinforcement Learning in MalmO (MARLO) Competition' aims to encourage research towards more general AI approaches through multi-player games. Games have a long and fruitful history of both serving as test beds to push AI research forward and being the first to benefit from novel research developments. It is our belief that this is the right time to focus on multi-player games in the more complex and diverse 3D environments provided by modern video games such as Minecraft.
The problem of learning in multi-agent settings is one of the fundamental problems in artificial intelligence research and poses unique research challenges. For example, the presence of independently learning agents can result in non-stationarity, and the presence of adversarial agents can hamper exploration and consequently the learning progress. In addition to being particularly challenging, progress in multi-agent learning has far-ranging application potential, in particular in modern multi-player video games, where novel AI agents have great potential to enable novel game experiences.
A key feature of multi-agent play in video game settings is a rich diversity of tasks. Modern video games consist of varied maps or levels, all spanned by the theme of the game but varying in interesting and surprising ways. Such diversity poses the challenge of learning to generalize across multiple related tasks. Exciting research on multi-task learning has addressed some of these challenges, but key questions remain. How well can state of the art approaches learn to generalize to variants of a previously learned game?
Goal of the workshop is to bring together researchers and practitioners with diverse backgrounds in artificial intelligence and gaming, to provide a ground for the fruitful exchange of ideas to help start tackling these exciting key challenges associated with multi-task, multi-agent game settings.
Topics:
We invite submissions on all aspects of learning in multi-task, multi-agent settings, especially where they relate to video games. These include, but are not limited to:
- Case studies
- Collaboration and competition
- Communication between agents
- Evaluation and testing
- Feedback and human-in-the-loop learning
- Interaction mechanisms
- Learning approaches
- Opponent modeling
- Scalability
- Systems
- Tools
In addition to novel research contributions, we invite the submission of extended abstracts that summarize recent published work that are related to the topic of the workshop. This is an opportunity for authors to present their work to the AIIDE community, and generate discussion and ideas for future work and collaboration.
We also specifically encourage submissions from teams planning to participate in the MARLO competition, for example with extended abstracts that detail their planned competition agents.
MARLO COMPETITTION
The Learning to Play workshop is associated with the MARLO (Multi-Agent Reinforcement Learning in MalmO) Competition, and will host a live tournament round. The competition asks participants to create agents that learn to play with and against other agents across a series of related mini-games that are implemented on top of the game Minecraft using the Malmo framework. It will be kicked off by August 2018, and will focus on learning to play in multi-agent, multi-task game settings.
Details of the MARLO competition will be posted at: https://www.crowdai.org/challenges/marlo-2018
IMPORTANT DATES
- Deadline for paper submission:
July 27, Extended! August 8 anywhere on earth - Review decisions released: August 24
- MARLO Competition Qualifying Round: entries due October 7
- Workshop and MARLO Final Round: November 14
PAPER SUBMISSION
We invite submission of extended abstracts (up to 2 pages, including references) of work in progress or summarising recent relevant publications, as well as full papers (up 4 pages) for novel research contributions or position papers. Submissions should be formatted using the AAAI template
Authors must register at the workshop paper submission site before they submit their papers. Abstracts and papers must be submitted through the submission website; we cannot accept submissions by email.
Please submit papers and extended abstracts on Easychair: https://easychair.org/conferences/?conf=aiide18 (select "AIIDE-18 Workshop: Learning to Play: The Multi-Agent Reinforcement Learning in Malmö" when creating a new submission).
CODE OF CONDUCT
The open exchange of ideas and the freedom of thought and expression are central to the aims and goals of the Learning to Play workshop at AIIDE 2018. The workshop organizers commit to providing a harassment-free, accessible, inclusive, and pleasant workshop experience with equity in rights for all. We want every participant to feel welcome, included, and safe at the workshop. We aim to provide a safe, respectful, and harassment-free workshop environment for everyone involved regardless of age, sex, gender, gender identity and expression, sexual orientation, (dis)ability, physical appearance, race, ethnicity, nationality, marital status, military status, veteran status, religious beliefs, dietary requirements, medical conditions, pregnancy-related concerns or childcare requirements. We also respect any other status protected by laws of the country in which the workshop or program is being held.
We do not tolerate harassment of workshop participants. We expect all interactions between AIIDE members to be respectful and constructive, including interactions during the review process, at the workshop itself, and on social media. Workshop participants who violate the terms of this policy may not be welcome to submit to or attend future AIIDE meetings. Concerns should be brought to the attention of the workshop organizers in person (if needed) and definitely in writing, and will be investigated and reviewed by AAAI and the AIIDE Steering Committee. If there is an immediate need for intervention, outside law enforcement authorities may need to be contacted.
(This code of conduct was adapted from the Code of Conduct from the ACM Special Interest Group on Computer Human Interaction. See: https://chi2017.acm.org/diversity-inclusion-statement.html )
Competition
Check the competition site at Crowd AI
Clone the framework from our repository
The Multi-Agent Reinforcement Learning in MalmÖ (MARLÖ) competition is a new challenge that proposes research on Multi-Agent Reinforcement Learning using multiple games. Participants would create learning agents that will be able to play multiple 3D games as defined in the MalmÖ platform built on top of Minecraft. The aim of the competition is to encourage AI research on more general approaches via multi-player games. For this, the challenge will consist of not one but several games, each one of them with several tasks of varying difficulty and settings. Some of these tasks will be public and participants will be able to train on them. Others, however, will be private, only used to determine the final rankings of the competition.
A framework will be provided with easy instructions to install, create the first agent and submit it to the competition server. Documentation, tutorials and sample controllers for the development of entries will also be accessible to the participants of this challenge. The competition will be hosted on CrowdAI.org, which will determine the preliminary rankings of the competition. Recurring tournaments at regular intervals will determine which agents perform better in the games proposed. This competition will be sponsored by Microsoft Research for framework development and competition awards.
One of the main features of this competition is that agents play in multiple games. Therefore, several tasks are proposed for this contest. For the purpose of this document and the competition itself, we define:
- Game: each one of the different scenarios in which agents play.
- Task: each instance of a game. Tasks, within a game, may be different to each other in terms of level layout, size, difficulty and other game-dependent settings.
The next figure sketches how games and tasks are organized in the challenge. As can be seen, tasks will be of public nature and accessible by the participants, while others are secret and will be used to evaluate the submitted entries at the end of the competition. Tasks are distributed across sets:
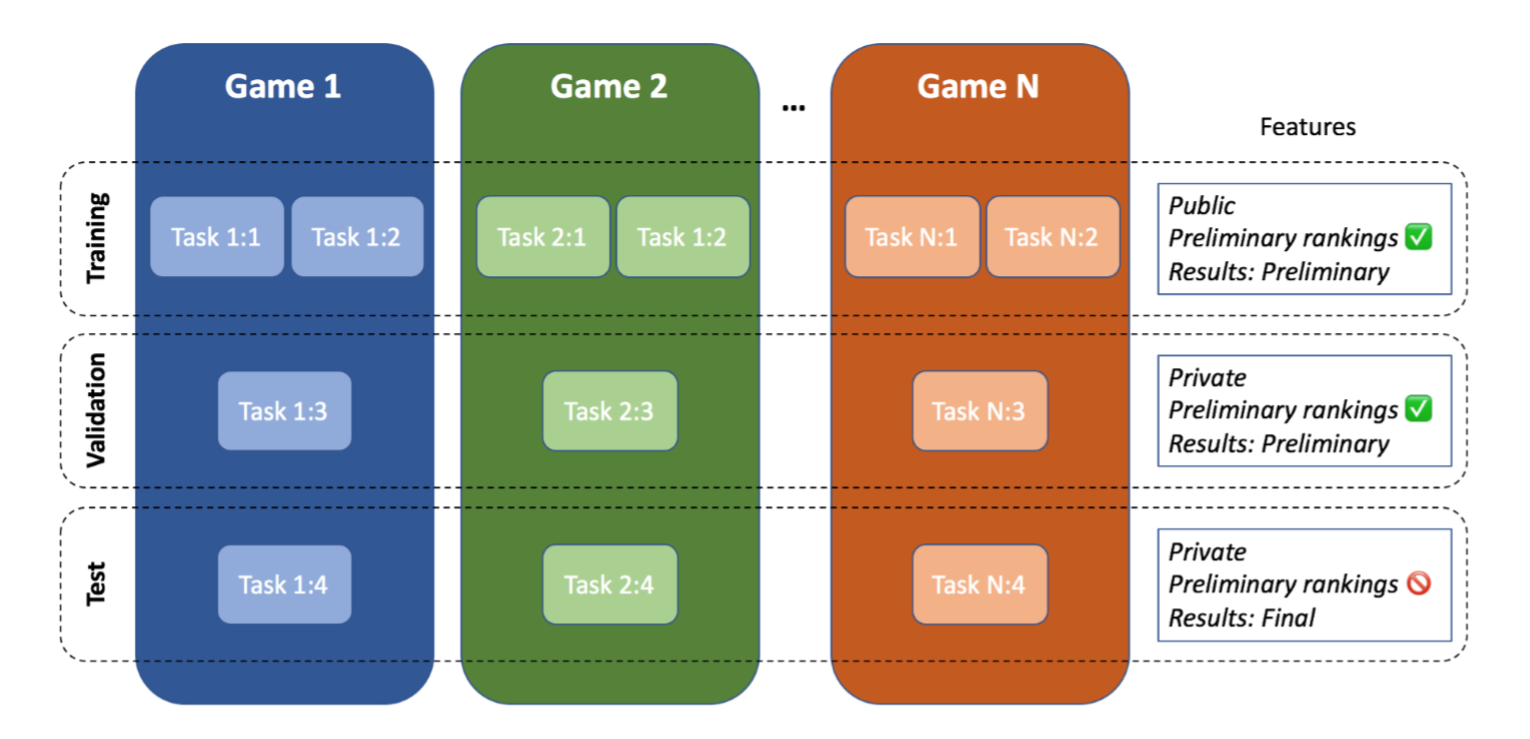
For more information about the competition, visit our Crowd AI competition site.
Program Committee
- Hendrik Baier, Researcher, Centrum Wiskunde & Informatica, Amsterdam (The Netherlands)
- Tim Brys, Post-Doctoral Researcher, Vrije Universiteit Brussel (Belgium)
- Jose Hernandez-Orallo, Professor at TU Valencia (Spain)
- Wojciech Jaskowsky, Assistant Professor, Poznan University of Technology (Poland)
- Michal Kempka, PhD Student, Poznan University of Technology (Poland)
- Jialin Liu, Res. Assist. Prof. at SUST (China)
- Simon M. Lucas, Professor at QMUL (UK)
- Ann Nowé, Professor at VUB (Belgium)
- Julien Pérolat, Research Scientist at Google Deepmind (UK)
- Edward Powley, Associate Professor at Falmouth University (UK)
- Marcel Salathé, Associate Professor at EPFL (Switzerland)
- Spyridon Samothrakis, Assistant Director at IADS, University of Essex (UK)
- Harm van Sejien, Research Manager, Microsoft Research Montreal (Canada)
- Marius Stanescu (University of Alberta)
- Vanessa Volz, PhD student at TU Dortmund (Germany)
- Peter Vrancx, Senior Machine Learning Researcher at Prowler.io (UK)
Organizing Committee
- Diego Perez-Liebana (Queen Mary University of London)
- Raluca D. Gaina (Queen Mary University of London)
- Daniel Ionita (Queen Mary University of London)
- Sharada P. Mohanty (École polytechnique fédérale de Lausanne)
- Sam Devlin (Microsoft Research)
- Andre Kramer (Microsoft Research)
- Noburu (Sean) Kuno (Microsoft Research)
- Katja Hofmann (Microsoft Research)
Contact
For queries about this workshop, please contact Diego Perez-Liebana
For queries about the competition, please refer to the contact section of our Crowd AI competition site.